pytorch
有关pytorch的学习网站:https://pytorch-cn.readthedocs.io/zh/latest/
另外一些有关pytorch的知识点如下
PyTorch中的Tensor张量
1.Tensor张量
我们可以将这个理解为矩阵
2.Tensor数据类型
(1)torch.FloatTensor()参数可以直接是一个元组然后转化为Tensor;或者是两个参数,n,m直接代表矩阵的维度已经形状。
(2)torch.IntTensor,用于生成数据类型为整形的tensor。
3.Tensor常用函数
(1)torch.rand # 用于生成数据类型为浮点型且维度指定的随机Tensor,和在Numpy中使用numpy.rand生成随机数的方法类似,随机生成的浮点数据在0~1区间均匀分布。
(2)torch.randn # 用于生成数据类型为浮点型且维度指定的随机Tensor,和在Numpy中使用numpy.randn生成随机数的方法类似,随机生成的浮点数的取值满足均值为0,方差为1的正太分布。
(3)torch.range # 用于生成数据类型为浮点型且自定义其实范围和结束范围的Tensor,所以传递给torch.range的参数有三个,分别是范围的起始值,范围的结束值和步长,其中,步长用于指定从起始值到结束值的每步的数据间隔。
(4)torch.zeros # 用于生成数据类型为浮点型且维度指定的Tensor,不过这个浮点型的Tensor中的元素值全部为0。
(5)torch.abs # 将参数传递到torch.abs后返回输入参数的绝对值作为输出,输出参数必须是一个Tensor数据类型的变量。
(6)torch.add # 将参数传递到torch.add后返回输入参数的求和结果作为输出,输入参数既可以全部是Tensor数据类型的变量,也可以是一个Tensor数据类型的变量,另一个是标量。
(7)torch.clamp # 对输入参数按照自定义的范围进行裁剪,最后将参数裁剪的结果作为输出。所以输入参数一共有三个,分别是需要进行裁剪的Tensor数据类型的变量、裁剪的上边界和裁剪的下边界,具体的裁剪过程是:使用变量中的每个元素分别和裁剪的上边界及裁剪的下边界的值进行比较,如果元素的值小于裁剪的下边界的值,该元素就被重写成裁剪的下边界的值;同理,如果元素的值大于裁剪的上边界的值,该元素就被重写成裁剪的上边界的值。
(8)torch.div # 将参数传递到torch.div后返回输入参数的求商结果作为输出,同样,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。(两个参数,第一个是被除数,第二个是除数)
(9)torch.pow # 将参数传递到torch.pow后返回输入参数的求幂结果作为输出,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
(10)torch.mul # 将参数传递到 torch.mul后返回输入参数求积的结果作为输出,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
(11)torch.mm # 将参数传递到 torch.mm后返回输入参数的求积结果作为输出,不过这个求积的方式和之前的torch.mul运算方式不太样,torch.mm运用矩阵之间的乘法规则进行计算,所以被传入的参数会被当作矩阵进行处理,参数的维度自然也要满足矩阵乘法的前提条件,即前一个矩阵的行数必须和后一个矩阵的列数相等,否则不能进行计算。
(12)torch.mv # 将参数传递到torch.mv后返回输入参数的求积结果作为输出,torch.mv运用矩阵与向量之间的乘法规则进行计算,被传入的参数中的第1个参数代表矩阵,第2个参数代表向量,顺序不能颠倒。
(以上基本都是二元运算,前面的参数是被运算的数,后面的是对前面多运算的参数,或者这个torch的实例直接去运行)
(13)torch.view # 改变一个 tensor 的大小或者形状。
神经网络堆叠
简易神经网络的堆叠
1 | # coding:utf-8 |
2.Pytorch自动梯度
autograd package 是PyTorch中所有神经网络的核心,它提供了Tensors上所有运算的自动求导功能,通过torch.autograd包,可以使模型参数自动计算在优化过程中需要用到的梯度值,在很大程度上帮助降低了实现后向传播代码的复杂度。
torch.autograd 包的主要功能是完成神经网络后向传播中的链式求导。
autograd.Variable 是这个package的中心类。它打包了一个Tensor,并且支持几乎所有运算。一旦你完成了你的计算,可以调用.backward(),所有梯度就可以自动计算。
3.使用自动梯度和自定义函数搭建简易神经网络模型
1 | import torch |
词向量学习
One hot编码
什么是One hot编码
one-hot编码,又称独热编码、一位有效编码。其方法是使用N位状态寄 存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在 任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行), 每个样本有三个特征(列),如下图:
| Feature_1 | Feature_2 | Feature_3 | |
|---|---|---|---|
| Sample1 | 1 | 4 | 3 |
| Sample2 | 2 | 3 | 2 |
| Sample3 | 1 | 2 | 2 |
| Sample4 | 2 | 1 | 1 |
上图中我们已经对每个特征进行了普通的数字编码:我们的feature_1有两种可能的取值,比如是男/ 女,这里男用1表示,女用2表示。
那么one-hot编码是怎么搞的呢?我们再拿feature_2来说明:这里 feature_2 有4种取值(状态),我们就用4个状态位来表示这个特 征,one-hot编码就是保证每个样本中的单个特征只有1位处于状态 1,其他的都是0。
1->0001
2->0010
3->0100
4->1000
对于2种状态、3种状态、甚至更多状态都可以这样表示,所以我们可以 得到这些样本特征的新表示,入下图:
| Feature_1 | Feature_2 | Feature_3 | |
|---|---|---|---|
| Sample1 | 01 | 1000 | 100 |
| Sample2 | 10 | 0100 | 010 |
| Sample3 | 01 | 0010 | 010 |
| Sample4 | 10 | 0001 | 001 |
one-hot编码将每个状态位都看成一个特征。对于前两个样本我们可以得到它的特征向量分别为
Sample_1->[0,1,1,0,0,0,1,0,0]
Sample_2->[1,0,0,1,0,0,0,1,0]
优缺点分析
优点:
1.解决了分类器不好处理离散数据的问题
2.在一定程度上也起到了扩充特征的作用
缺点:
1.在文本特征上缺点就非常突出了
2.它是一个提词袋不考虑词与词之间的顺序
3.他假 设词与词相互独立(在大多数情况下,词与词是相互影响的)
4.他得到的特征是稀疏的
word2vec相关概念
2013年Google团队发表了word2vec工具。word2vec工具主要包含两个模型:跳字模型(skip-gram)和连续词袋模型(continuous bag of words,简称CBOW),以及两种高效训练的方法:负采样(negative samoling)和层序softmax(hierarchical softmax),值得一提的是,word2vec词向量可以较好的表达不同词之间类似和类比关系。
模型:
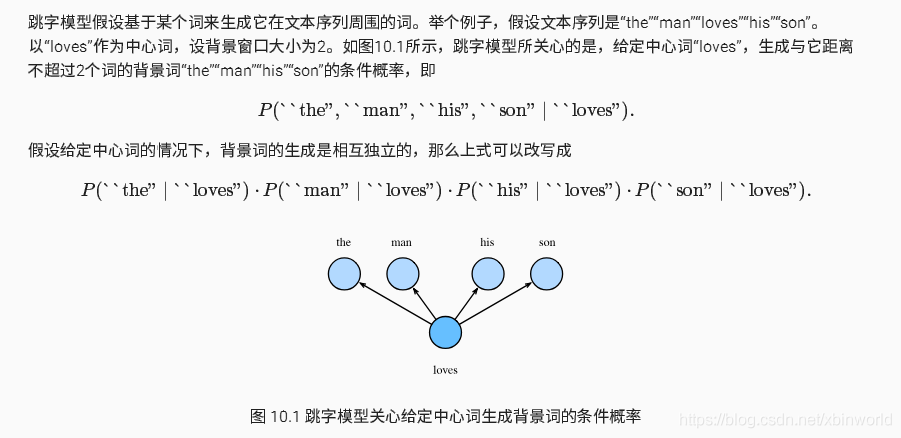
跳字模型:
在跳字模型中,我们用一个词来预测它在文本序列周围的词。例如,给定文本“the”,“main”,“hit”,“his”和“son”,跳字模型所关心的是,给定“hit”,生成它的临近词“the”,“main”,“hit”和“son”的概率

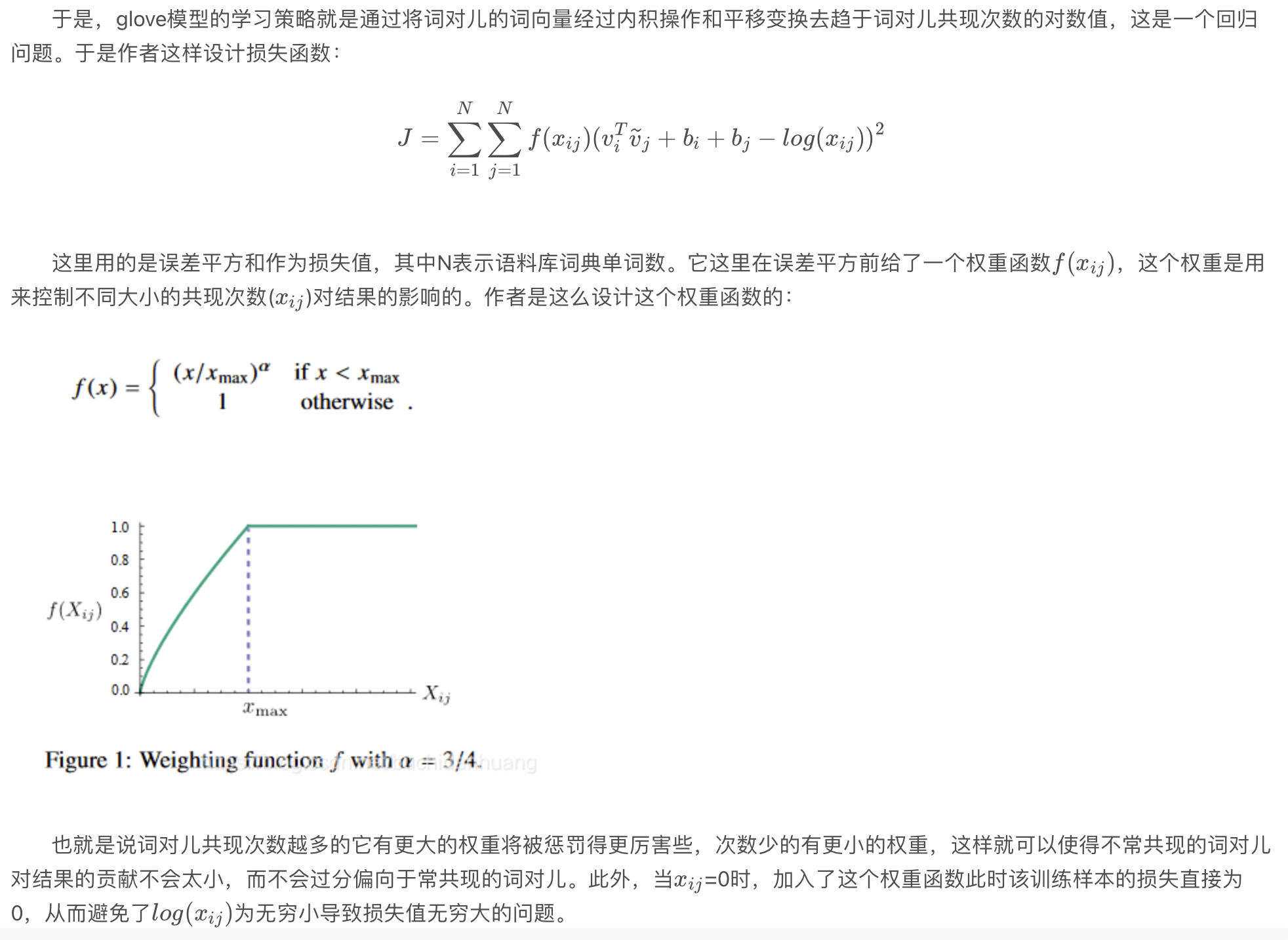
上述公式中,T表示窗口中心词的位置,m表示的窗口的大小。这样就可以计算出每个中心词推断背景词的概率,而我们在输入的时候给出了背景词的向量,此时只需要最大化背景词的输出概率即可。 基于这样的想法,我们会想到极大化似然估计的方式。但是一个函数的最大值往往不容易计算,因此,我们可以通过对函数进行变换,从而改变函数的增减性,以便优化。
注解:看到这里,就引出了word2vec的核心方法,其实就是认为每个词相互独立,用连乘来估计最大似然函数,求解目标函数就是最大化似然函数。上面公式涉及到一个中心词向量v,以及背景词向量u,因此呢很有趣的是,可以用一个input-hidden-output的三层神经网络来建模上面的skip-model。
Skip-gram可以表示为由输入层(Input)、映射层(Projection)和输出层(Output)组成的神经网络(示意图如下):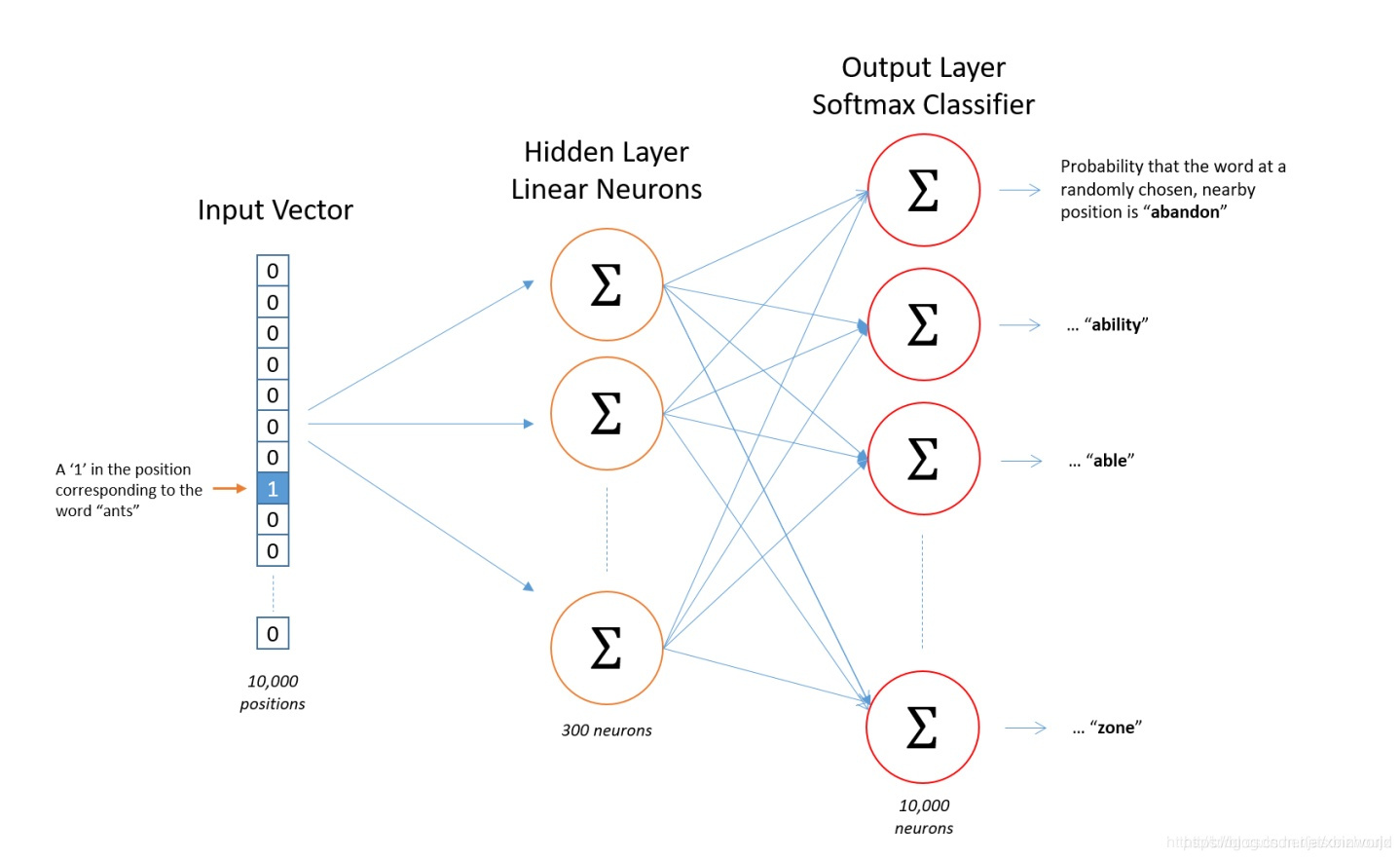
1.输入的表示:输入层中每个词由独热编码方式表示,即所有词均表示成一个N维向量,其中N为词汇表中单词的总数。在向量中,每个词都将与之对应的维度置为1,其余维度的值均为0。
2.网络中传播的前向过程:输出层向量的值可以通过隐含层向量(K维),以及连接隐藏层和输出层之间的KxN维权重矩阵计算得到。输出层也是一个N维向量,每维与词汇表中的一个单词相对应。最后对输出层向量应用Softmax激活函数,可以计算每一个单词的生成概率。
训练:
注解:上面的公式每一步都推荐推到一下,都很基础。上面只求了对中心词向量v的梯度,同理对背景词向量的梯度,也很容易计算出来。然后就采用传统的梯度下降(一般采用sgd)来训练词向量(其实我们最后关心的是中心词向量来作为词的表征。)
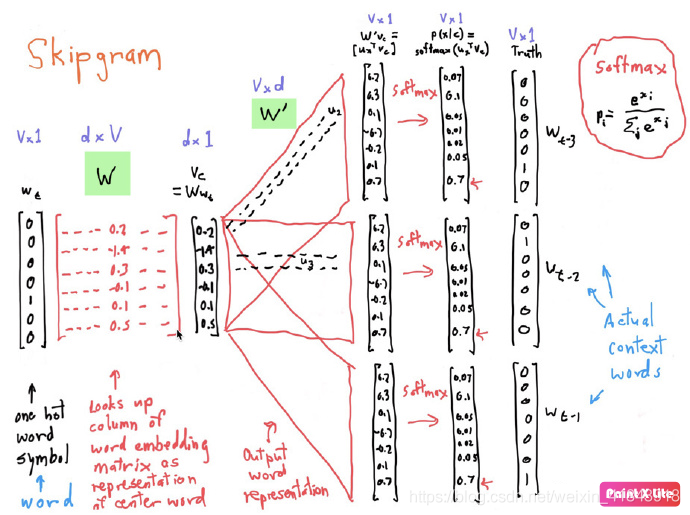
这里有一个key point说下,也许大家也想到了:词向量到底在哪里呢?回看下前面图1,有两层神经网络,第一层是input层到hidden层,这个中间的weight矩阵就是词向量!!!
假设input的词汇表N长度是10000,hidden层的长度K=300,左乘以一个10000长度one-hot编码,实际上就是在做一个查表!因此,这个weight矩阵的行就是10000个词的词向量。很有创意是不是?再来看神经网络的第二层,hidden到out层,中间hidden层有没有激活函数呢?从前面建模看到,u和v是直接相乘的,没有激活层,所以hidden是一个线性层。out层就是建模了v和u相乘,结果过一个softmax,那么loss函数是最大似然怎么办呢?其实就是接多个只有一个true label(背景词)的cross entropy loss,把这些loss求和。因为交叉熵就是最大似然估计,如果这点不清楚的可以去网上搜一下,很容易知道。
所以呢,我们即可用前面常规的最大似然建模来理解如何对u和v的进行优化求解;也完全可以把skip-model套到上面图1这样的一个简单神经网络中,然后就让工具自己来完成weight的训练,就得到了我们想要的中心词向量。
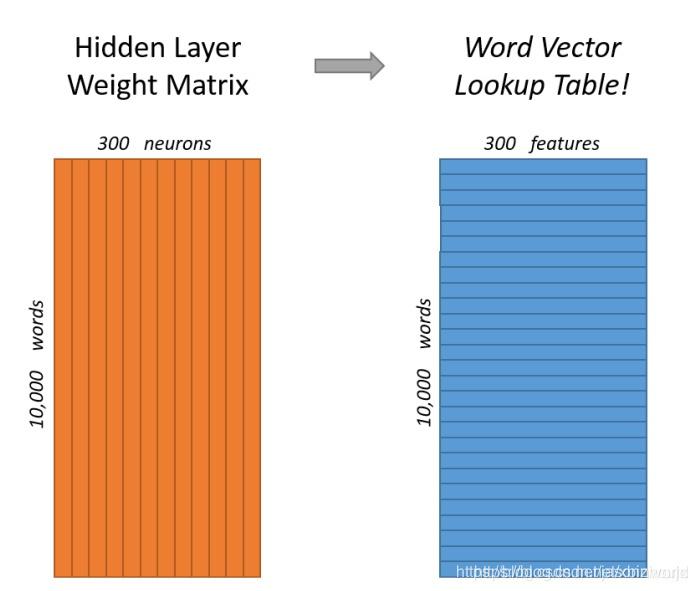
下图是对这个过程的简单可视化过程示意图。左边矩阵为词汇表中第四个单词的one-hot表示,右边矩阵表示包含3个神经元的隐藏层的权重矩阵,做矩阵乘法的结果就是从权重矩阵中选取了第四行的权重。因此,这个隐藏层的权重矩阵就是我们最终想要获得的词向量字典[2]
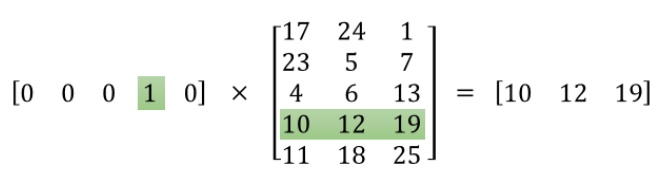
获取训练样本:按照上下文窗口的大小从训练文本中提取出词汇对,下面以句子The quick brown fox jumps over the lazy dog为例提取用于训练的词汇对,然后将词汇对的两个单词使用one-hot编码就得到了训练用的train_data和target_data。 下面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。Training Samples(输入, 输出)示意图如下:
如果使用随机梯度下降,那么在每一次迭代里我们随机采样一个较短的子序列来计算有关该子序列的损失,然后计算梯度来更新模型参数。
连续词袋模型(CBOW)
CBOW就倒过来,用多个背景词来预测一个中心词,CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好[2]。但是方法和上面是很像的,因此这里我就放下图。推导的方法是一样的。
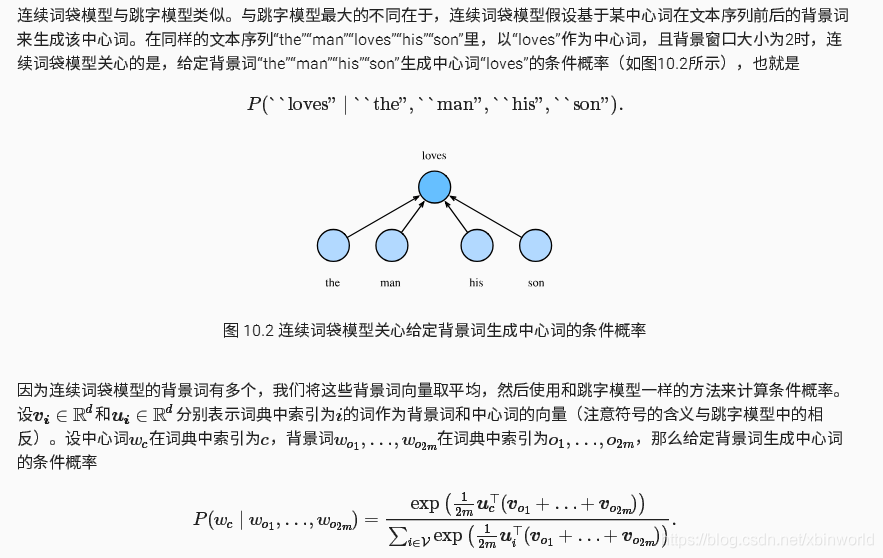
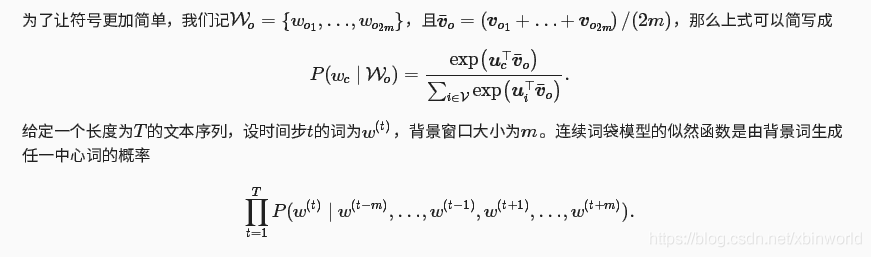
我们发现,不论是跳字模型(skip-gram) 还是连续词袋模型(CBOW),我们实际上都是取得input-hidden这个词向量(weight矩阵),而不是后面带着loss那一部分,这样我们也很容易可以对loss(训练方法)进行修改,这个也是下一篇要说的内容:
问:每次梯度的计算复杂度是多少?当词典很大时,会有什么问题?
word2vec作者很创造性地提出了2种近似训练方法(分层softmax(hierarchical softmax)和负采样(negative sampling)),得益于此,可以训练大规模语料库。
wordvrc优化方式
近似训练
负采样



层序softmax
一、h-softmax
在面对label众多的分类问题时,fastText设计了一种hierarchical softmax函数。使其具有以下优势:
(1)适合大型数据+高效的训练速度:能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”,特别是与深度模型对比,fastText能将训练时间由数天缩短到几秒钟。
(2)支持多语言表达:利用其语言形态结构,fastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。
可以认为,FastText= (word2vec中)CBOW + h-softmax;其结构为:输入 - 隐层 - h-softmax
基本原理
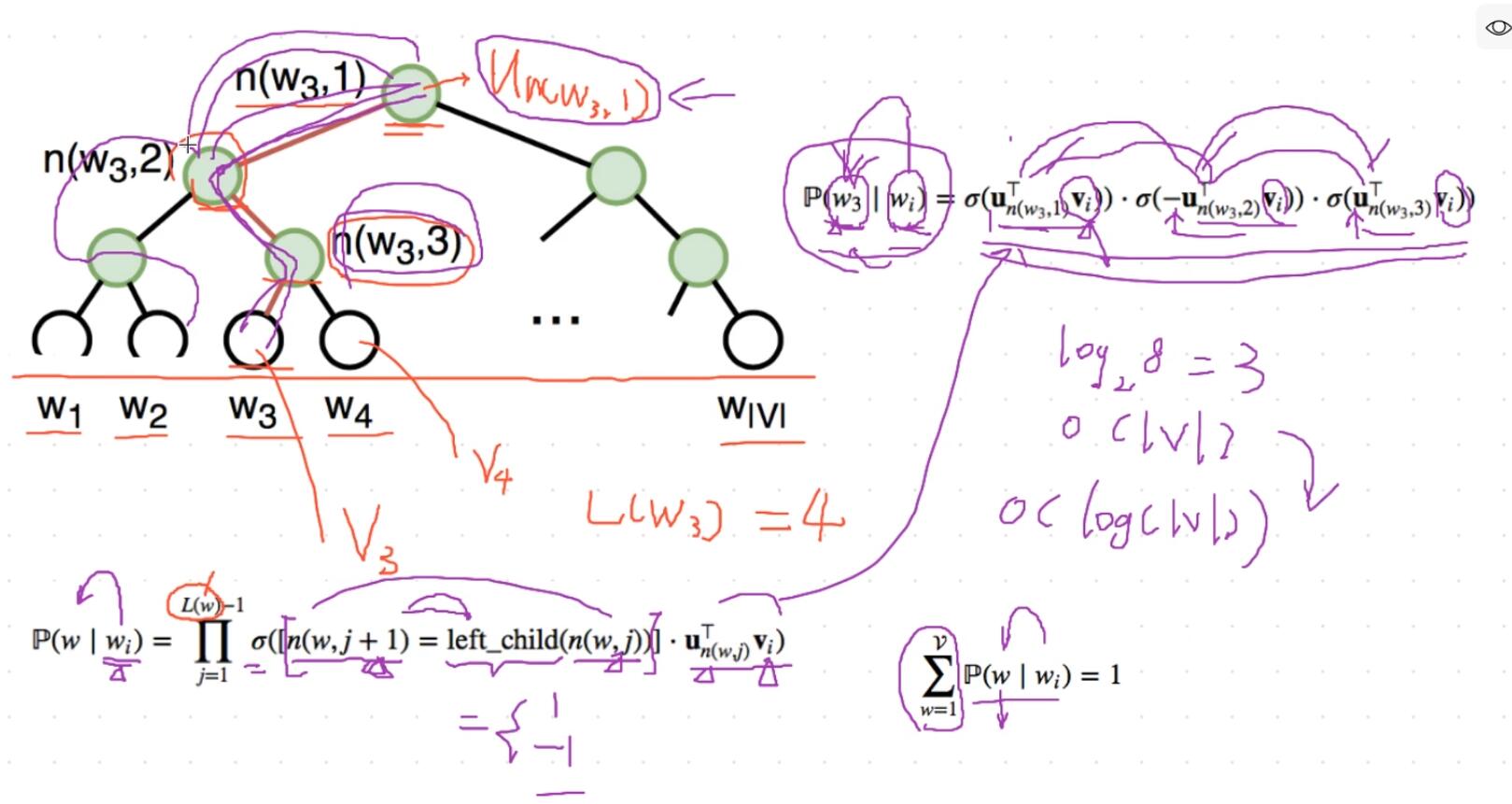
根据标签(label)和频率建立霍夫曼树;(label出现的频率越高,Huffman树的路径越短)
Huffman树中每一叶子结点代表一个label;
二、理论分析
层次之间的映射
将输入层中的词和词组构成特征向量,再将特征向量通过线性变换映射到隐藏层,隐藏层通过求解最大似然函数,然后根据每个类别的权重和模型参数构建Huffman树,将Huffman树作为输出。
模型的训练
Huffman树中每一叶子结点代表一个label,在每一个非叶子节点处都需要作一次二分类,走左边的概率和走右边的概率,这里用逻辑回归的公式表示
模型的训练
Huffman树中每一叶子结点代表一个label,在每一个非叶子节点处都需要作一次二分类,走左边的概率和走右边的概率,这里用逻辑回归的公式表示
模型的训练
Huffman树中每一叶子结点代表一个label,在每一个非叶子节点处都需要作一次二分类,走左边的概率和走右边的概率,这里用逻辑回归的公式表示

how fast

word2vec实现方式
word2vec实战
Glove
预备知识
共现概率:
什么是共现?
单词 i i i出现在单词 j j j的环境中(论文给的环境是以 j j j为中心的左右10个单词区间)叫共现。
什么是共现矩阵?
单词对共现次数的统计表。我们可以通过大量的语料文本来构建一个共现统计矩阵。
例如,有语料如下:
I like deep learning
I like NLP
I enjoy flying
我以窗半径为1来指定上下文环境,则共现矩阵就应该是
| count | I | like | enjoy | deep | learning | NLP | flying |
|---|---|---|---|---|---|---|---|
| I | 0 | 2 | 1 | 0 | 0 | 0 | 0 |
| like | 2 | 0 | 0 | 1 | 0 | 1 | 0 |
| enjoy | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| deep | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| learning | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| NLP | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| flying | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
因为我们的窗口半径为1,所以对于上面我们的每一句语句来说,进行分析然后统计来看,最后出来的表上诉